【教程】從零開始構建最小高可用 k3s 集群
作者序
本文轉載自 我的博客站,原文地址: 【教程】從零開始搭建最小高可用 k3s 集群
在一切開始之前,請注意以下事項:
- 本文所使用的開發環境為 ArchLinux + Fish Shell,由於跨系統指令語法不一定完全兼容,請根據自己的實際情況調整指令格式。
- 本文中的指令依賴於各類CLI工具(已在文中標註或是在前置教程中已經安裝過,linux系統常見的CLI工具不會在文中標註),由於CLI工具的安裝過程較為繁瑣且對於各個平台的安裝步驟並不一致,此處不再贅述,請參考官方文檔的安裝教程。
引言
眾所周知,k3s 是由 Rancher Labs 開發的輕量級 Kubernetes 發行版,也是目前最流行的 K8s 輕量化方案。
相較於傳統運維方式(1Panel/寶塔/SSH 等),k3s 的學習曲線更陡峭,需要理解更多容器編排概念。但一旦掌握,你將獲得:
k3s 的核心優勢
- 輕量高效 - 單個二進制文件,內存佔用 < 512MB,完美適配低配 VPS
- 生產就緒 - 完全兼容 Kubernetes API,可平滑遷移到標準 K8s
- 聲明式運維 - 用 YAML 描述期望狀態,系統自動維護
- 高可用保障 - 自動故障恢復 + 多節點負載均衡
- 開箱即用 - 內置網絡、存儲、Ingress 等核心組件
通過 k3s,我們可以將多台廉價 VPS 整合為企業級高可用集群,實現傳統運維難以達到的自動化水平。
目標讀者與準備
適合人群
- 有一定 Linux 基礎的開發者
- 希望從傳統運維過渡到容器編排
- 想搭建個人高可用服務的技術愛好者
前置知識
- 熟悉 Linux 命令行操作
- 了解 Docker 容器基礎
- 具備基本的網絡知識(SSH、防火牆)
學習收獲
完成本教程後,你將掌握:
- 使用 k3sup 快速部署 k3s 集群
- 理解 k3s 核心組件(API Server、etcd、kubelet 等)的作用
- 替換默認組件優化性能(Cilium CNI、Nginx Ingress 等)
- 部署第一個應用並配置外部訪問
- 基本的集群運維和故障排查技巧
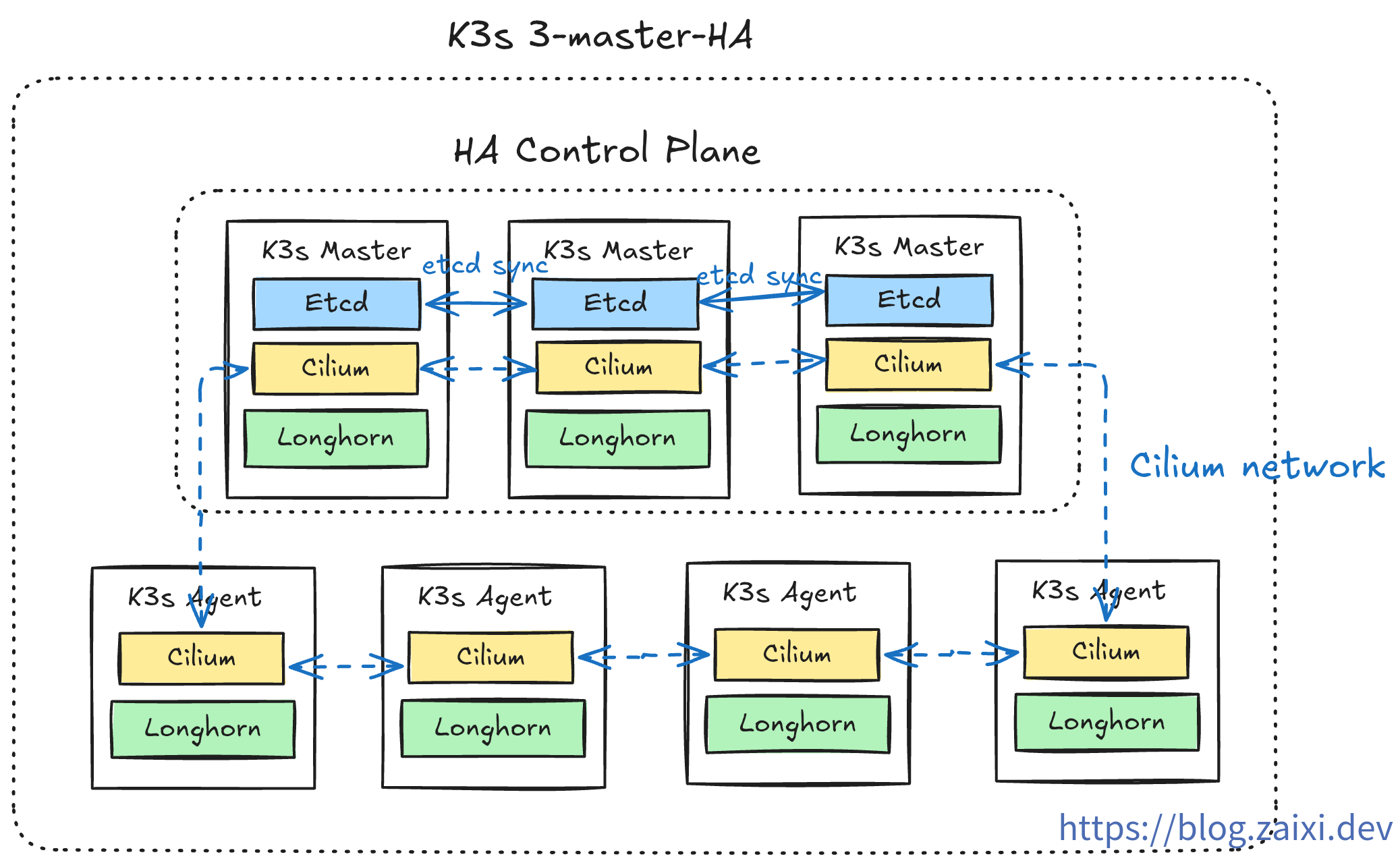
部署規劃
k3s 默認安裝了一套精簡組件,為了滿足生產級訴求,我們需要提前規劃哪些模塊要保留或替換。下表展示了推薦的取捨策略:
| 組件類型 | k3s 默認組件 | 替換組件 | 替換理由 | k3sup 禁用參數 |
|---|---|---|---|---|
| 容器運行時 | containerd | - | 保持默認即可 | - |
| 數據存儲 | SQLite / etcd | - | 單節點用 SQLite,集群用 etcd | - |
| Ingress Controller | Traefik | Nginx Ingress / 其他 | 團隊更熟悉、功能需求不同 | --disable traefik |
| LoadBalancer | Service LB (Klipper-lb) | 外部負載均衡 | 雲廠商(例如Cloudflare)提供的負載均衡更加成熟強大 | --disable servicelb |
| DNS | CoreDNS | - | 保持默認即可 | - |
| Storage Class | Local-path-provisioner | Longhorn | 分佈式存儲、高可用、備份能力 | --disable local-storage |
| CNI | Flannel | Cilium | eBPF 性能、網絡策略、可觀測性 | --flannel-backend=none --disable-network-policy |
環境準備
必備工具
搭建集群前需要準備三款 CLI 工具:k3sup、kubectl、Helm。請參考各自的官方文檔安裝,這裡不再展開,安裝完成後,可以通過 k3sup version、kubectl version、helm version 等命令進行驗證。

服務器要求
準備至少三台雲服務器(示例環境使用 Ubuntu 24.04),作為最小化三節點高可用控制平面(推薦配置 ≥ 4C4G)。提前記錄各節點 IP、確認 SSH 公鑰已分發,並知曉本地私鑰路徑,後續步驟會用到。
部署初始控制平面
使用 k3sup 部署初始控制節點:
k3sup install \
--ip 初始節點 IP \
--user root \
--ssh-key 密鑰位置 \
--k3s-channel latest \
--cluster \
--k3s-extra-args "--disable traefik --disable servicelb --disable local-storage --flannel-backend=none --disable-network-policy"
如圖所示:
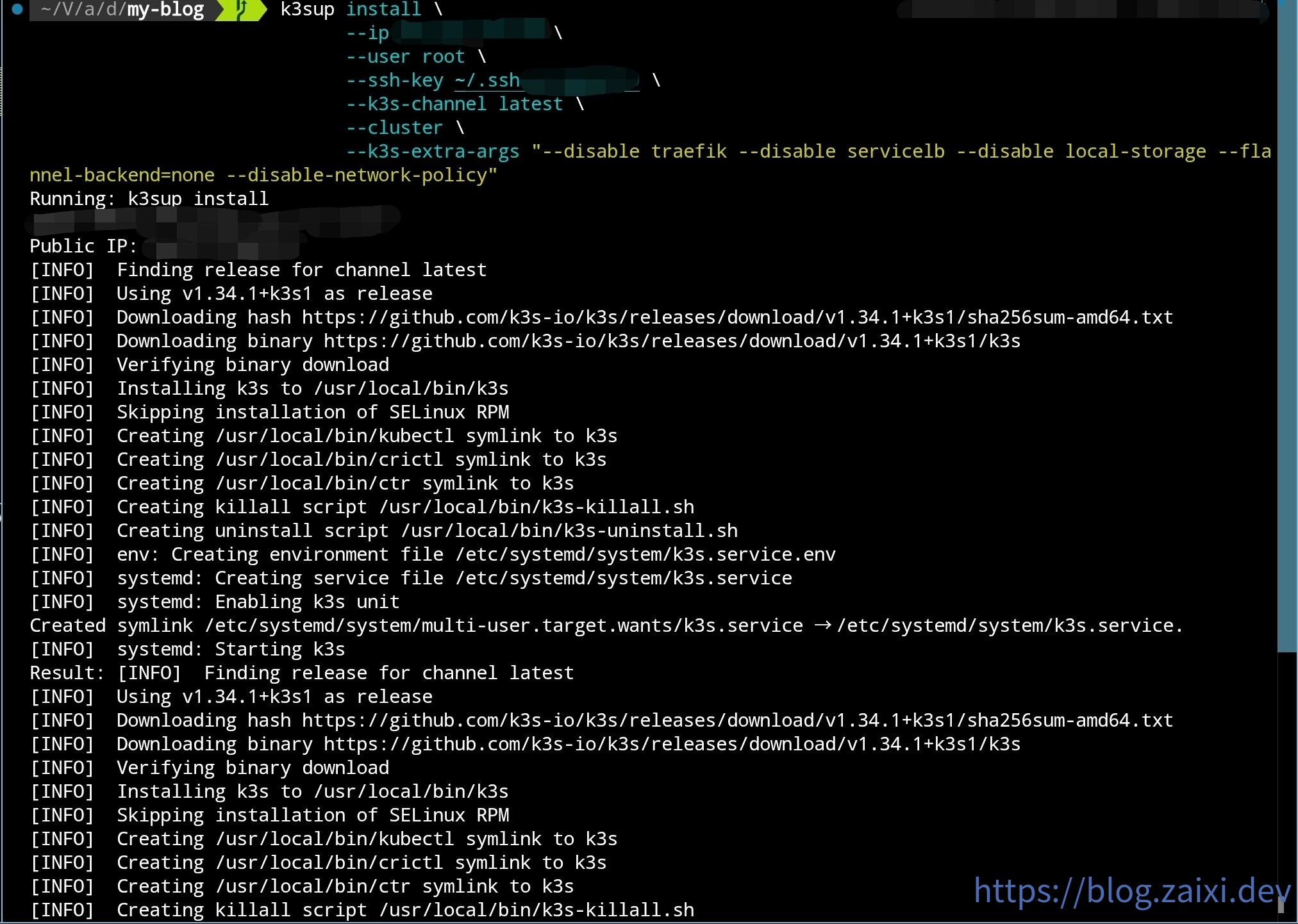
安裝完成後,k3sup 會自動將 kubeconfig 複製到當前目錄。雖然可以直接使用這份配置,但更加穩健的做法是與現有配置文件合併。
合併 kubeconfig
- 備份當前的 kubeconfig(默認位於
~/.kube/config):
cp ~/.kube/config ~/.kube/config.backup
fish shell(僅供參考):
cp $KUBECONFIG {$KUBECONFIG}.backup
- 將新舊 kubeconfig 合併為一份扁平文件:
KUBECONFIG=~/.kube/config:./kubeconfig kubectl config view --flatten > ~/.kube/config.new
fish shell(僅供參考):
KUBECONFIG=$KUBECONFIG:./kubeconfig kubectl config view --flatten > kubeconfig-merged.yaml
- 檢查新文件內容無誤後覆蓋舊配置:
mv ~/.kube/config.new ~/.kube/config
fish shell:
mv ./kubeconfig-merged.yaml $KUBECONFIG
- 驗證新上下文是否生效:
kubectl config get-contexts
kubectl config use-context default
安裝 Cilium(替代 Flannel)
安裝 k3s 時我們禁用了默認 CNI(Flannel),因此節點暫時無法互通。按計劃部署 Cilium 以提供網絡與網絡策略能力。
使用 Helm 安裝 Cilium:
# 添加 Cilium Helm 倉庫
helm repo add cilium https://helm.cilium.io/
# 更新 Helm 倉庫
helm repo update
# 安裝 Cilium CNI(單副本,默認模式)
helm install cilium cilium/cilium \
--namespace kube-system \
--set operator.replicas=1 \
--set ipam.mode=kubernetes
如果集群已經禁用 kube-proxy,可額外添加
--set kubeProxyReplacement=strict。本教程保持默認值以兼容更多場景。
執行完成後可以看到:

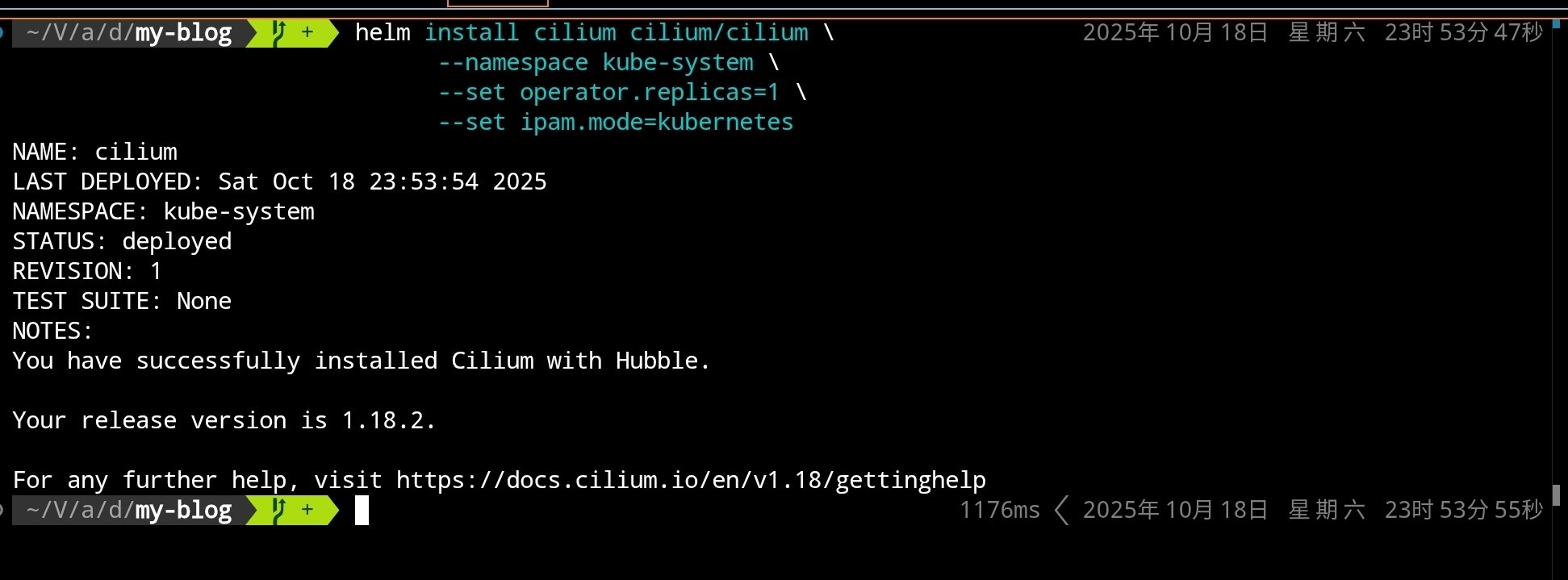
等待 Cilium 組件啟動完成:
# 查看 Cilium 相關 Pod 狀態
kubectl get pods -n kube-system -l k8s-app=cilium
# 查看節點狀態(應該從 NotReady 變為 Ready)
kubectl get nodes

節點切換到 Cilium 後應當從 NotReady 變為 Ready。接下來使用 k3sup 加入另外兩個控制節點。
擴容控制平面
為了實現高可用,我們需要至少 3 個控制節點。使用以下命令加入第二個控制節點:
k3sup join \
--ip 第二個節點 IP \
--user root \
--ssh-key 密鑰位置 \
--server-ip 初始節點 IP \
--server \
--k3s-channel latest \
--k3s-extra-args "--disable traefik --disable servicelb --disable local-storage --flannel-backend=none --disable-network-policy"
同樣的方式加入第三個控制節點:
k3sup join \
--ip 第三個節點 IP \
--user root \
--ssh-key 密鑰位置 \
--server-ip 初始節點 IP \
--server \
--k3s-channel latest \
--k3s-extra-args "--disable traefik --disable servicelb --disable local-storage --flannel-backend=none --disable-network-policy"
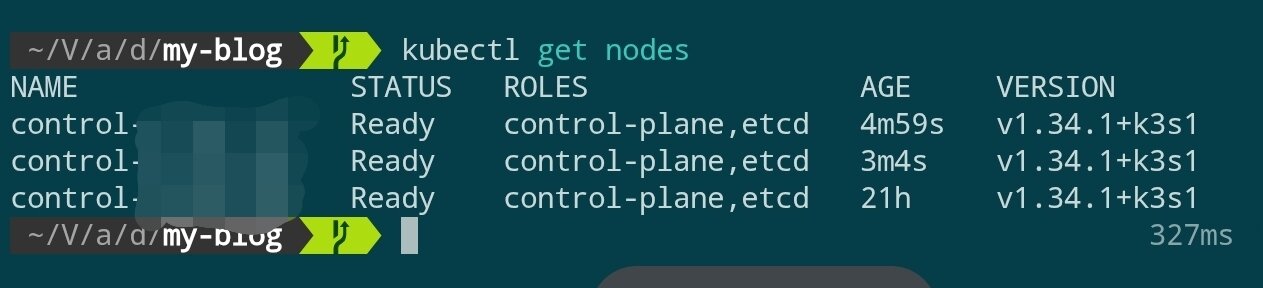
等待幾分鐘後檢查集群狀態:
kubectl get nodes
當三個控制節點均處於 Ready 狀態時,控制平面即告搭建完成。
安裝 Nginx Ingress Controller
替換 k3s 默認的 Traefik,安裝 Nginx Ingress Controller:
# 添加 Nginx Ingress Helm 倉庫
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
# 安裝 Nginx Ingress Controller(可能需要等待很久)
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--create-namespace \
--set controller.hostPort.enabled=true \
--set controller.hostPort.ports.http=80 \
--set controller.hostPort.ports.https=443 \
--set controller.service.type=ClusterIP
kubectl get pods -n ingress-nginx
kubectl get svc -n ingress-nginx
由於我們啟用了 hostPort,Service 類型會顯示為 ClusterIP,不會自動分配雲廠商的外部地址,例如:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller ClusterIP 10.43.25.32 <none> 80/TCP,443/TCP 1d
ingress-nginx-controller-admission ClusterIP 10.43.184.196 <none> 443/TCP 1d
此時入口其實就是每個控制節點本身的公網 IP,可通過 kubectl get nodes -o wide 或直接查詢雲主機面板來確認,後續在配置 Cloudflare DNS 時填入該 IP 即可。

安裝 Longhorn 分佈式存儲
Longhorn 是由 Rancher 開發的雲原生分佈式塊存儲系統,提供高可用、備份、快照等企業級功能。相比 k3s 默認的 local-path-provisioner,Longhorn 支持跨節點的持久化存儲。
前置依賴檢查
在安裝 Longhorn 之前,需要確保每個節點都安裝了必要依賴;若希望通過 Ansible 批量處理,可參考後續示例:
# 在每個節點上執行(通過 SSH)
# 檢查並安裝 open-iscsi
apt update
apt install -y open-iscsi nfs-common
# 啟動並設置開機自啟
systemctl enable --now iscsid
systemctl status iscsid
如果希望使用 Ansible 批量安裝依賴,可以參考以下任務片段:
---
- name: Setup K3s nodes with Longhorn dependencies and CrowdSec
hosts: k3s
become: true
vars:
crowdsec_version: "latest"
tasks:
# ============================================
# Longhorn Prerequisites
# ============================================
- name: Install Longhorn required packages
ansible.builtin.apt:
name:
- open-iscsi # iSCSI support for volume mounting
- nfs-common # NFS support for backup target
- util-linux # Provides nsenter and other utilities
- curl # For downloading and API calls
- jq # JSON processing for Longhorn CLI
state: present
update_cache: true
tags: longhorn
- name: Enable and start iscsid service
ansible.builtin.systemd:
name: iscsid
enabled: true
state: started
tags: longhorn
- name: Load iscsi_tcp kernel module
community.general.modprobe:
name: iscsi_tcp
state: present
tags: longhorn
- name: Ensure iscsi_tcp loads on boot
ansible.builtin.lineinfile:
path: /etc/modules-load.d/iscsi.conf
line: iscsi_tcp
create: true
mode: '0644'
tags: longhorn
- name: Check if multipathd is installed
ansible.builtin.command: which multipathd
register: multipathd_check
failed_when: false
changed_when: false
tags: longhorn
- name: Disable multipathd if installed (conflicts with Longhorn)
ansible.builtin.systemd:
name: multipathd
enabled: false
state: stopped
when: multipathd_check.rc == 0
tags: longhorn
部署 Longhorn
使用 Helm 安裝 Longhorn:
# 添加 Longhorn Helm 倉庫
helm repo add longhorn https://charts.longhorn.io
helm repo update
# 安裝 Longhorn(可能需要等待較長時間),請注意這裡為了節約硬盤空間,只設置了單副本,請根據需求自行調整
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespace \
--set defaultSettings.defaultDataPath="/var/lib/longhorn" \
--set persistence.defaultClass=true \
--set persistence.defaultClassReplicaCount=1
等待 Longhorn 組件啟動:
# 查看 Longhorn 組件狀態
kubectl get pods -n longhorn-system
# 查看 StorageClass
kubectl get storageclass

訪問 Longhorn UI(可選)
Longhorn 提供了一個 Web UI 用於管理存儲卷。可以通過端口轉發臨時訪問:
# 端口轉發到本地
kubectl port-forward -n longhorn-system svc/longhorn-frontend 8081:80
# 在瀏覽器訪問 http://localhost:8081
完成查看後,請在終端按
Ctrl+C停止端口轉發,避免持續佔用本地端口。
加入 Agent 節點
目前為止,我們搭建了一個 3 節點的高可用控制平面(control-plane)。在生產環境中,我們不希望在 control-plane 節點上運行實際的應用程序(會佔用 API Server、etcd 等核心組件的資源)。
因此,我們需要加入專門用於運行工作負載(Pods)的 Agent 節點(也稱為 Worker 節點)。
安裝前置依賴
與 control-plane 節點一樣,Agent 節點也需要滿足 Longhorn 的依賴(若希望這些節點能夠調度並存儲持久卷)。
在所有準備加入的 Agent 節點上,提前執行以下命令:
# 在每個 Agent 節點上執行(通過 SSH)
apt update
apt install -y open-iscsi nfs-common
# 啟動並設置開機自啟
systemctl enable --now iscsid
執行加入命令
添加 Agent 節點的命令與添加 control-plane 節點幾乎一致,但有兩個關鍵區別:不使用 --server 標記且無需額外參數。
k3sup join \
--ip <AGENT_節點 IP> \
--user root \
--ssh-key <密鑰位置> \
--server-ip <任意 Control 節點 IP> \
--k3s-channel latest
驗證節點狀態
可以一次性加入多個 Agent 節點。添加完成後等待幾分鐘,Cilium 與 Longhorn 的組件會自動調度到新節點。
使用 kubectl 查看集群狀態:
kubectl get nodes -o wide
你應該能看到新加入的節點,其 ROLE 列顯示為 <none>(在 k3s 中,<none> 即代表 agent/worker 角色)。
同時,你可以監控 Cilium 和 Longhorn 的 Pod 是否在新節點上成功啟動:
# Cilium agent 應該會在新節點上啟動
kubectl get pods -n kube-system -o wide
# Longhorn instance-manager 應該也會在新節點上啟動
kubectl get pods -n longhorn-system -o wide
至此,集群已經擁有了高可用的控制平面和用於運行應用的工作節點。
安裝 Argo CD(GitOps 持續交付)
為了讓集群具備聲明式持續交付能力,我們可以安裝 Argo CD,它能夠將 Git 倉庫中的 Kubernetes 清單自動同步到集群,配合前文部署的 Cilium、Ingress、Longhorn 等組件即可構成完整的 GitOps 流程。
安裝步驟
# 添加 Argo Helm 倉庫並更新索引
helm repo add argo https://argoproj.github.io/argo-helm
helm repo update
# 在 argocd 命名空間中安裝 Argo CD(默認使用 ClusterIP Service)
helm install argocd argo/argo-cd \
--namespace argocd \
--create-namespace \
--set controller.replicas=2 \
--set redis-ha.enabled=false \
--set server.service.type=ClusterIP
上述參數含義如下:
argocd:安裝 release 的名稱,後續升級/卸載都依賴這個名字。argo/argo-cd:使用argoHelm 倉庫中的argo-cdchart。--namespace argocd:將所有資源安裝到argocd命名空間。--create-namespace:若命名空間不存在則自動創建。--set controller.replicas=2:將 Argo CD 控制器副本數設為 2,提升高可用能力。--set redis-ha.enabled=false:關閉 Redis HA,默認單實例即可滿足多數開發/測試場景。--set server.service.type=ClusterIP:server 服務使用 ClusterIP 類型,後續我們通過 Ingress 暴露對外訪問。
安裝完成後等待所有組件就緒:
kubectl get pods -n argocd
你應該能看到類似如下的輸出,表明核心組件均已成功啟動:
NAME READY STATUS RESTARTS AGE
argocd-application-controller-0 1/1 Running 0 30s
argocd-application-controller-1 1/1 Running 0 17s
argocd-applicationset-controller-6bf5957996-xnn7c 1/1 Running 0 30s
argocd-dex-server-7cb4b74df8-vqkdv 1/1 Running 0 30s
argocd-notifications-controller-5cbffcc56d-9gntp 1/1 Running 0 30s
argocd-redis-b5f4d9475-584fs 1/1 Running 0 30s
argocd-redis-secret-init-sggs2 0/1 Completed 0 47s
argocd-repo-server-7687bd88c6-4ksfp 1/1 Running 0 30s
argocd-server-67ccc4d44c-6th5p 1/1 Running 0 30s
其中:
argocd-application-controller-*:負責同步 Application 資源狀態,我們設置了兩個副本以提高可用性。argocd-applicationset-controller:負責 ApplicationSet CRD 的編排。argocd-dex-server:提供 Dex 身份認證服務。argocd-notifications-controller:實現通知與告警能力。argocd-redis-*:Argo CD 的內置 Redis 用於緩存集群狀態(redis-secret-initJob 初始化密鑰後處於Completed狀態屬於正常現象)。argocd-repo-server:處理 Git 倉庫同步與模板渲染。argocd-server:提供 Web/UI 與 gRPC API。
所有 Pod 狀態為 Running 或 Completed 即表示 Argo CD 安裝成功,可以繼續配置訪問入口或應用同步。
訪問 Web UI
由於我們已經部署了 ingress-nginx,可通過 Ingress 暴露 Argo CD UI(將 argocd.example.com 換成自己的域名或臨時 hosts):
# argocd-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: argocd-server-ingress
namespace: argocd
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
spec:
ingressClassName: nginx
rules:
- host: argocd.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: argocd-server
port:
number: 443
kubectl apply -f argocd-ingress.yaml
第一次登錄需要使用初始管理員密碼,可通過以下命令獲取並自行修改:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 --decode
隨後訪問 https://argocd.example.com 並使用用戶名 admin 登錄即可。建議在首次登錄後立即更改密碼或配置 SSO,並通過 Git 倉庫創建第一個 Application,開啟你的 GitOps 工作流。
如果你使用 Cloudflare 託管域名,可以按以下步驟完成域名解析:
- 將 Ingress 示例中的
argocd.example.com替換為自己在 Cloudflare 上託管的真實域名 - 在 Cloudflare 控制台 → DNS → 添加一條
A記錄,名稱為上述子域,值填寫集群入口的公網 IP。若 Ingress Controller 啟用了hostPort,入口就是任一控制節點的公網 IP;若使用外部負載均衡,則填對應的負載均衡地址。 - 視需求選擇是否啟用 Cloudflare 代理(橙色雲朵)。開啟後建議為 Argo CD 配置受信任證書(例如使用 cert-manager 申請 Let's Encrypt)。
- 完成解析後,等待 DNS 生效即可通過 Cloudflare 提供的域名訪問 Argo CD UI。如需自動管理解析,可結合 external-dns + Cloudflare API Token 實現全自動的 GitOps 域名同步。
下一步
【教程】從零開始構建企業級高可用 PostgreSQL 集群