【教程】從零開始構建企業級高可用 PostgreSQL 集群

作者序
本文轉載自 我的博客站 ,原文地址:【教程】從零開始構建企業級高可用 PostgreSQL 集群
在一切開始之前,請注意以下事項:
- 本文默認你已經完成【教程】從零開始搭建最小高可用 k3s 集群
- 本文所使用的開發環境為
ArchLinux+Fish Shell,由於跨系統指令語法差異,請根據自己的實際情況調整指令格式。 - 本文所使用的對象存儲服務為一款兼容 S3 協議的對象存儲,請根據自己的實際情況調整配置方式。
- 本文中的指令依賴於各類CLI工具(已在文中標註或是在前置教程中標註,linux系統常見的CLI工具不會在文中標註),由於CLI工具的安裝過程較為繁瑣且對於各個平台的安裝步驟並不一致,此處不再贅述,請參考官方文檔的安裝教程。
引言
PostgreSQL 是功能最強大的開源關係型數據庫(具體優點網上已經被介紹過很多次了,這裡不再贅述),這也是筆者用的最多的關係型數據庫(沒有之一),因此在本人的教程中,所使用的關係型數據庫一般以PostgreSQL為主,因此你可以將這篇教程視作Kubernetes相關教程中的一篇非常基礎的前置教程
接下來說下這個CloudNativePG(CNPG),它是什麼東西呢?簡而言之,你可以將它視作是PostgreSQL在Kubernetes的特化版本,大幅簡化了PostgreSQL部署與管理的過程,同時也為了滿足企業級的要求,它提供了很多的高級特性,包括高可用(HA)、自動化備份、故障演練、自動化擴展等。
本教程將基於 k3s + Longhorn,使用 CloudNativePG 以及通用的 S3 兼容對象存儲,從零搭建一套高可用 PostgreSQL 集群,並演示基礎的備份、運維操作,最後的最後,我們會手動創造故障,測試數據庫的自動化恢復能力
前置條件
在開始部署前,請確保以下前提已經滿足:
基礎設施
首先,你需要準備一個類似於
【教程】從零開始搭建最小高可用 k3s 集群 中的最小高可用k3s集群
CLI 工具
在開始教程前,你需要準備以下 CLI 工具:
kubectl,用於集群的管理,在上篇教程中,我們已經安裝了kubectl,並配置了對遠程集群的管理權限(kubeconfig)- 驗證指令:
kubectl version --short - 理想輸出:顯示
Client Version: <client_version>;正常連通時會額外返回Server Version: <server_version>
- 驗證指令:
helm, 用於部署 Operator,在上篇教程中,我們已經安裝了helm,並配置了對遠程集群的管理權限(即kubeconfig)- 驗證指令:
helm version - 理想輸出:
version.BuildInfo字段中包含Version: <helm_version>、GitCommit: <commit_hash>等信息
- 驗證指令:
kubeseal, 用於加密 Kubernetes Secret,請參考官方教程自行安裝- 驗證指令:
kubeseal --version - 理想輸出:輸出
kubeseal version: <kubeseal_version>
- 驗證指令:
openssl, 用於生成隨機密碼,這個一般系統自帶,如果沒有,可以參考官方教程自行安裝- 驗證指令:
openssl version - 理想輸出:輸出 OpenSSL 版本信息(如
OpenSSL <openssl_version> ...)
- 驗證指令:
第三方基礎設施
你需要準備一個 S3 兼容的對象存儲服務賬號(如 AWS S3、Wasabi、Backblaze B2 或自建 MinIO),並確保能夠創建 Bucket 與訪問密鑰
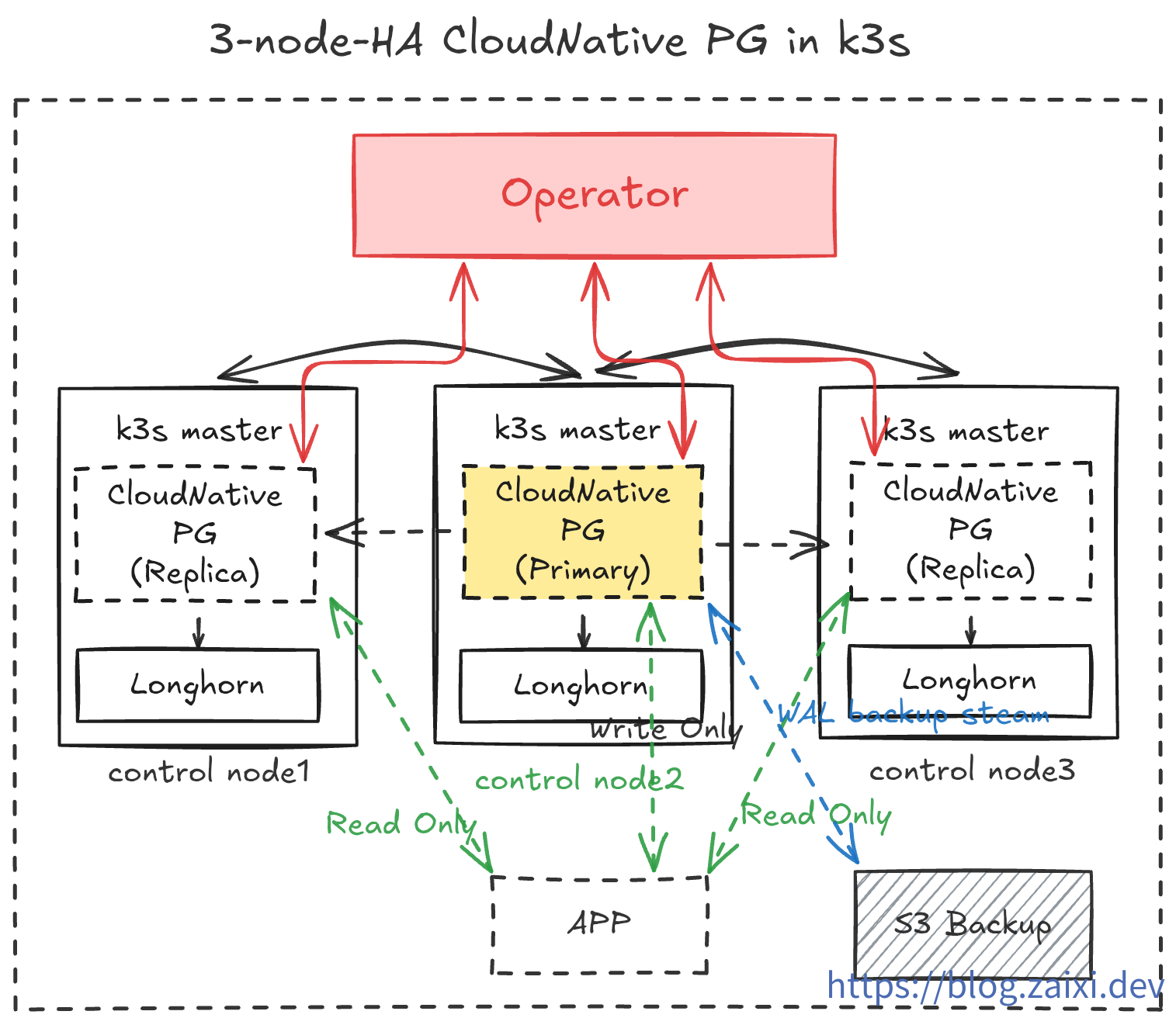
部署架構概覽
在本教程中,我們將實現如下操作:
- 在
cnpg-system命名空間中運行 CloudNativePG Operator。 - 在
data-infra命名空間中創建一個 3 副本的 PostgreSQL 集群(1 Primary + 2 Replica)。 - 啟用
barman持續備份到對象存儲,並為應用暴露一個 ReadWrite Service。 - 借助
cloudflared側載容器安全地將數據庫暴露到公網,用於開發測試。 - 運維演習,測試數據庫的滾動更新與插件安裝。
- 災難演習,隨機讓節點爆炸,觀察自動恢復能力。測試在極端環境下用對象存儲中的備份數據重建數據庫。
- 實現可觀察性,通過
Prometheus與Grafana監控數據庫狀態。
步驟一:安裝 CloudNativePG Operator
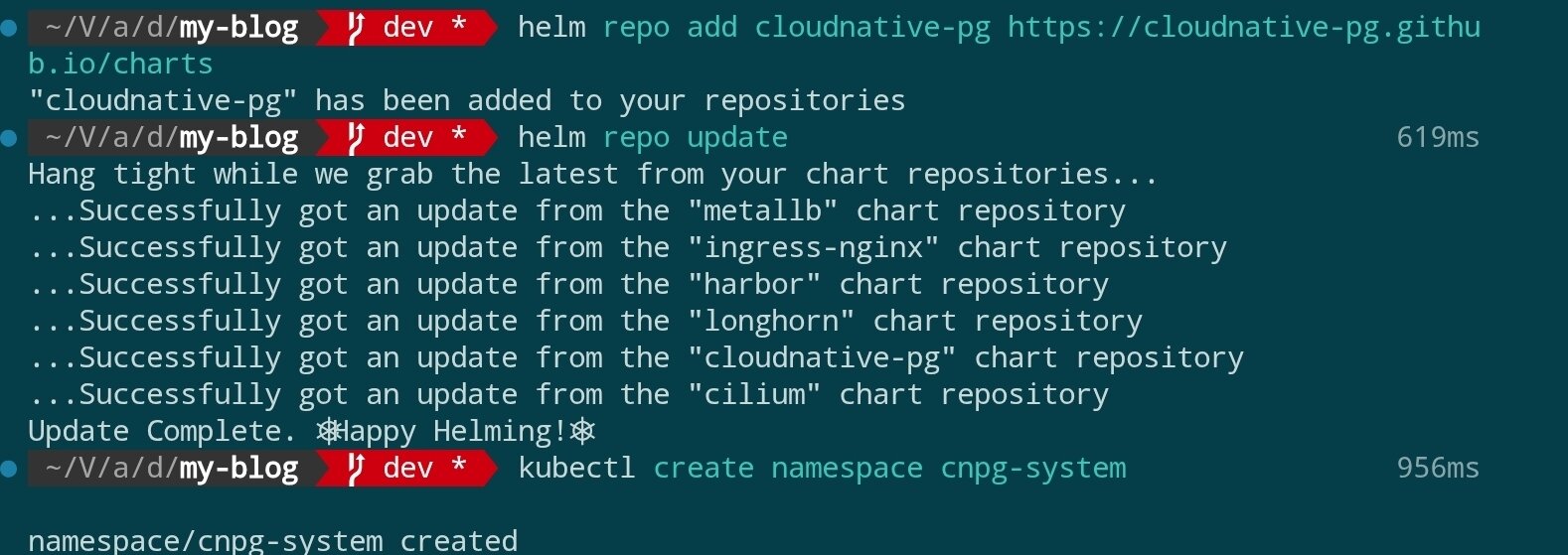
官方推薦使用 Helm 部署 Operator。首先添加 Helm 倉庫並完成安裝:
helm repo add cloudnative-pg https://cloudnative-pg.github.io/charts
helm repo update
kubectl create namespace cnpg-system
helm upgrade --install cloudnative-pg cloudnative-pg/cloudnative-pg \
--namespace cnpg-system \
--set controllerManager.resources.requests.cpu=200m \
--set controllerManager.resources.requests.memory=256Mi \
--set controllerManager.resources.limits.cpu=500m \
--set controllerManager.resources.limits.memory=512Mi
結果如圖:

安裝指令參數解釋:
| 參數/片段 | 作用 | 備註 |
|---|---|---|
helm upgrade --install | 若 Release 已存在則升級,否則首次安裝 | 保持部署命令冪等 |
cloudnative-pg | Helm Release 的名稱 | Helm 用於追蹤本次部署 |
cloudnative-pg/cloudnative-pg | Chart 的倉庫與名稱 | 需提前 helm repo add cloudnative-pg … |
--namespace cnpg-system | 使用的 Kubernetes 命名空間 | Operator 將在該命名空間運行 |
--set controllerManager.resources.requests.cpu=200m | Controller Manager 請求的最低 CPU | 保證調度至少 0.2 核 |
--set controllerManager.resources.requests.memory=256Mi | Controller Manager 請求的最低內存 | 保證調度至少 256Mi |
--set controllerManager.resources.limits.cpu=500m | Controller Manager 的 CPU 上限 | 超過 0.5 核將被限制 |
--set controllerManager.resources.limits.memory=512Mi | Controller Manager 的內存上限 | 超過 512Mi 可能觸發 OOM |
如果你希望固定 Chart 或鏡像版本,可顯式加上
--version <chartVersion>與--set image.tag=<controllerTag>。省略這些參數時,Helm 會使用倉庫當前最新穩定版本以及 Chart 默認鏡像。
調度機制補充:
controllerManagerPod 由 Kubernetes Scheduler 負責調度,先篩掉不滿足資源請求(至少 200m CPU 與 256Mi 內存)的節點,再根據集群當前負載打分,最終選擇最合適的節點。如果沒有額外的nodeSelector、污點容忍或親和性設置,它可能落在任意一個滿足條件的節點上,但結果是依據算法和節點狀態計算出來的,而非完全隨機。
如果集群啟用了
kube-router、Cilium等網絡策略,請確保cnpg-system命名空間內的控制器可以訪問 Kubernetes API 與目標命名空間。
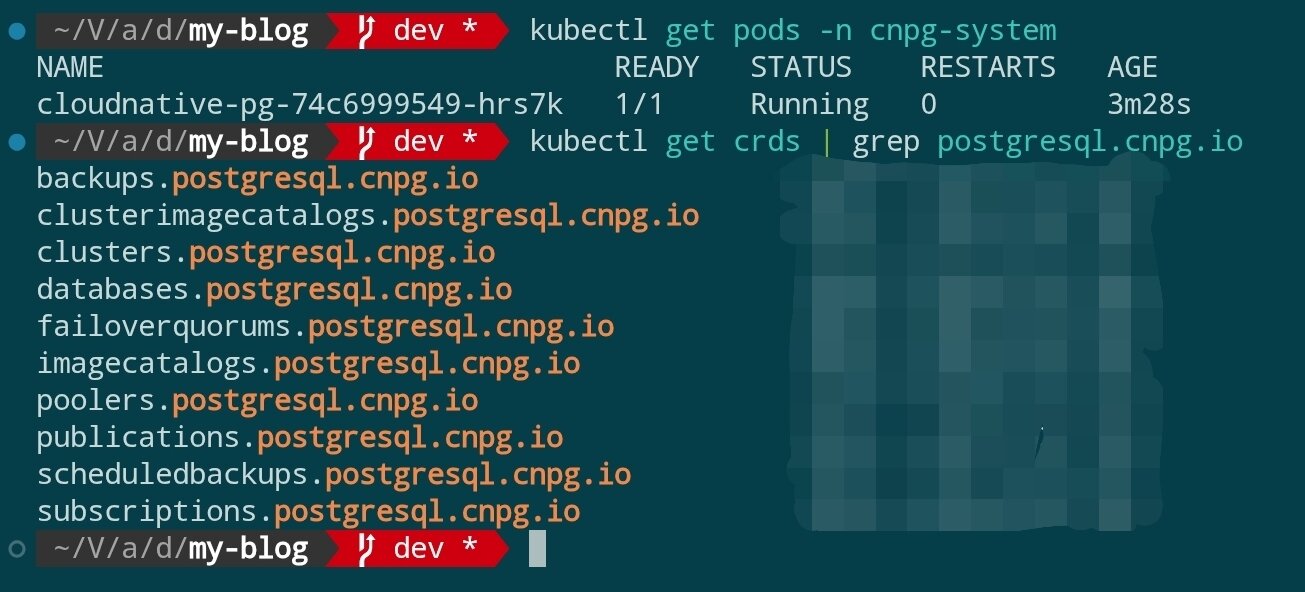
安裝完成後,驗證 Operator 是否就緒:
kubectl get pods -n cnpg-system
kubectl get crds | grep postgresql.cnpg.io
你應該能看到 cluster.postgresql.cnpg.io 等 CRD 已註冊,Operator Pod 處於 Running 狀態。
步驟二:準備命名空間與訪問憑證
安裝 Sealed Secrets
本次教程裡,我們需要使用 Sealed Secrets 管理敏感信息。使用 Sealed Secrets 前,需要在集群部署控制器並在本地安裝 kubeseal CLI:
常見問題
- Q:為什麼要引入 Sealed Secrets?
A:Sealed Secrets 可以把 Kubernetes Secret 加密成 Git 可安全保存的清單。即使存入版本庫也不會泄露明文,集群側的控制器會按權限解封生成真實 Secret,讓敏感配置可以使用標準 GitOps 流程同步。
helm repo add sealed-secrets https://bitnami-labs.github.io/sealed-secrets
helm repo update
kubectl create namespace sealed-secrets
helm upgrade --install sealed-secrets sealed-secrets/sealed-secrets \
--namespace sealed-secrets \
--set fullnameOverride=sealed-secrets-controller
上述命令會在
sealed-secrets命名空間運行控制器,名稱固定為sealed-secrets-controller,便於後續示例引用。若集群已有現成部署,可跳過此步驟。
下一步,在本地安裝 kubeseal 並執行 kubeseal --version 驗證版本,請參考官方安裝教程。

注意:
kubeseal默認會去kube-system命名空間尋找名為sealed-secrets-controller的服務。如果像示例一樣放在sealed-secrets命名空間,且沒有指定參數,就會看到error: cannot get sealed secret service: services "sealed-secrets-controller" not found。因此後續命令務必顯式傳入--controller-namespace sealed-secrets --controller-name sealed-secrets-controller,或根據實際安裝位置調整。
常見問題
- Q:為什麼運行
kubeseal會提示error: cannot get sealed secret service: services "sealed-secrets-controller" not found?
A:kubeseal會默認去kube-system命名空間尋找同名服務。示例中我們把控制器部署在sealed-secrets命名空間,因此需要加上--controller-namespace sealed-secrets --controller-name sealed-secrets-controller,否則就會找不到。 - Q:既然如此,為什麼不直接把服務部署在
kubeseal默認能找到的kube-system命名空間?
A:主要是為了隔離和易維護。kube-system一般由集群底層組件佔用,保持該命名空間純淨便於排障。同時獨立的sealed-secrets命名空間能集中管理相關資源,在多環境或多租戶時也方便做權限控制。工具默認指向kube-system是為了兼容常見安裝方式,我們只需按實際部署傳參即可。
生成業務 Secret
為數據庫層準備單獨的命名空間,並使用 Sealed Secrets 管理敏感信息,避免雜項資源混在同一空間:
kubectl create namespace data-infra
生成數據庫應用賬戶的加密 Secret:
Step 1:生成原始 Secret 清單(不會寫入集群)
kubectl create secret generic cnpg-app-user \
--namespace data-infra \
--from-literal=username=app_user \
--from-literal=password="$(openssl rand -base64 20)" \
--dry-run=client -o json > cnpg-app-user.secret.json
該命令將用戶名和隨機密碼封裝成 Kubernetes Secret 的 JSON 清單並寫入 cnpg-app-user.secret.json,同時保持對集群無副作用。生成的文件內容類似:
{
"kind": "Secret",
"apiVersion": "v1",
"metadata": {
"name": "cnpg-app-user",
"namespace": "data-infra"
},
"data": {
"password": "random-password",
"username": "random-username"
}
}
Step 2:使用 kubeseal 加密成 SealedSecret
kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml < cnpg-app-user.secret.json > cnpg-app-user.sealed-secret.yaml
這裡手動讀取前一步的 JSON 並交給 kubeseal。命名空間和控制器參數確保 CLI 能連接上我們部署的 Sealed Secrets 控制器,--format yaml 則輸出可提交到 Git 的 SealedSecret 文件,此處生成的文件內容類似於:
---
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: cnpg-app-user
namespace: data-infra
spec:
encryptedData:
password: random-password(locked)
username: random-username(locked)
template:
metadata:
name: cnpg-app-user
namespace: data-infra
Step 3:將 SealedSecret 應用到集群並刪除原始 Secret
kubectl apply -f cnpg-app-user.sealed-secret.yaml
rm cnpg-app-user.secret.json
控制器接收後會自動解封並生成同名的常規 Secret(cnpg-app-user),供後續數據庫資源引用。妥善保管好cnpg-app-user.sealed-secret.yaml,以便在後續的CICD流程中使用。
準備 S3 兼容對象存儲憑證
- 登錄對象存儲服務控制台(如 AWS S3、Wasabi、Backblaze B2 或自建 MinIO 集群),新建一個專用的 Bucket,示例命名
cnpg-backup,Region 選擇距離 Kubernetes 集群最近的區域。 - 在 Bucket 的訪問策略中關閉公共讀寫,只允許憑證訪問;如供應商支持生命週期或版本管理,可根據合規需求提前配置。
- 進入憑證或密鑰管理頁面,為本教程創建一對 Access Key,至少授予目標 Bucket 的
Object Read與Object Write權限,必要時可限制在特定前綴範圍。 - 記錄控制台返回的
Access Key ID、Secret Access Key、Region(若適用)以及 S3 Endpoint,例如https://s3.ap-northeast-1.amazonaws.com或供應商提供的自定義域名。部分廠商會注明是否要求 Path Style 訪問,請同步記下。 - 將這些信息保存到密碼庫,並準備好後續寫入 Kubernetes Secret 的明文值:
aws_access_key_id、aws_secret_access_key、region(若未固定 Region 可填供應商推薦值),同時確認 CNPG 中將使用的destinationPath(形如s3://my-cnpg-backups/production)。
完成控制台配置後,即可繼續使用 Sealed Secrets 管理這組憑證喵。
使用 SealedSecret 配置對象存儲憑證
計劃啟用對象存儲備份時,同樣使用 Sealed Secrets 生成訪問憑證(以 S3 兼容服務為例):
kubectl create secret generic cnpg-backup-s3 \
--namespace data-infra \
--from-literal=aws_access_key_id=AKIA... \
--from-literal=aws_secret_access_key=xxxxxxxxxxxx \
--from-literal=region=ap-northeast-1 \
--dry-run=client -o json \
| kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml > cnpg-backup-s3.sealed-secret.yaml
kubectl apply -f cnpg-backup-s3.sealed-secret.yaml
步驟三:聲明 PostgreSQL 集群
CloudNativePG 使用 Cluster 自定義資源來定義數據庫棧。下面是一個生產友好的示例(存儲類使用上一教程部署好的 Longhorn):
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cnpg-ha
namespace: data-infra
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:16.4
primaryUpdateStrategy: unsupervised
storage:
size: 40Gi
storageClass: longhorn
postgresql:
parameters:
max_connections: "200"
shared_buffers: "512MB"
wal_level: logical
pg_hba:
- hostssl all all 0.0.0.0/0 md5
authentication:
superuser:
secret:
name: cnpg-app-user
replication:
secret:
name: cnpg-app-user
bootstrap:
initdb:
database: appdb
owner: app_user
secret:
name: cnpg-app-user
backup:
barmanObjectStore:
destinationPath: s3://my-cnpg-backups/production
endpointURL: https://s3.ap-northeast-1.amazonaws.com
s3Credentials:
accessKeyId:
name: cnpg-backup-s3
key: aws_access_key_id
secretAccessKey:
name: cnpg-backup-s3
key: aws_secret_access_key
region:
name: cnpg-backup-s3
key: region
retentionPolicy: "14d"
monitoring:
enablePodMonitor: true
保存為 cnpg-ha.yaml 並應用:
kubectl apply -f cnpg-ha.yaml
CNPG 會自動創建 StatefulSet、PVC、服務等資源。等待 Pod 啟動完成:
kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha -w
當 Primary 與 Replica 都處於 Running 狀態時,數據庫集群即部署完成。
步驟四:驗證高可用與服務暴露
檢查服務與連接信息
kubectl get svc -n data-infra -l cnpg.io/cluster=cnpg-ha
kubectl port-forward svc/cnpg-ha-rw 6432:5432 -n data-infra
psql "postgresql://app_user:$(kubectl get secret cnpg-app-user -n data-infra -o jsonpath='{.data.password}' | base64 -d)@127.0.0.1:6432/appdb"
CNPG 默認會創建 -rw(讀寫)與 -ro(只讀)Service,方便應用分別接入主庫與備庫。
模擬故障切換
強制刪除 Primary Pod 驗證自動恢復能力:
kubectl delete pod -n data-infra \
$(kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary -o jsonpath='{.items[0].metadata.name}')
幾秒鐘內,CNPG 會自動將一個 Replica 提升為 Primary。通過下列命令確認角色變化:
kubectl get pods -n data-infra -L role
kubectl logs -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary --tail=20
步驟五:備份與災備策略
- 持續備份(PITR):
barmanObjectStore配置將 WAL 持續寫入對象存儲,可通過kubectl cnpg backup命令觸發全量備份。 - 定期演練恢復:在臨時命名空間中創建
Backup+ClusterCR,驗證從對象存儲恢復到指定時間點。 - 監控與告警:開啟
monitoring.enablePodMonitor後,可在 Prometheus 中抓取cnpg_pg_replication_lag、cnpg_pg_is_in_recovery等關鍵指標。 - 資源配額:為
data-infra命名空間配置LimitRange與ResourceQuota,防止數據庫實例擠佔節點資源。
常見運維操作
- 在線擴容:調整
spec.instances數量即可,CNPG 會自動創建新的 Replica 並同步數據。 - 參數調整:更新
spec.postgresql.parameters,Operator 會觸發滾動重啟完成配置下發。 - 版本升級:修改
spec.imageName指定新版本鏡像,CNPG 會先創建新 Replica,執行switchover後再回收舊主庫。 - 邏輯複製:通過
pg_hba與wal_level配置,可以將特定庫/表同步到外部數據倉庫。
總結與下一步
至此,我們已經在高可用 k3s 集群上部署了一套具備自動故障切換、持續備份、聲明式管理能力的 PostgreSQL 集群。下一步可以考慮:
- 引入 Grafana Loki 或 ELK 收集數據庫日誌,完善觀測能力。
- 使用 CloudNativePG Pooler 或 PgBouncer 優化連接池管理。
- 結合 Argo CD/Fleet 等 GitOps 工具,將數據庫 CR 納入持續交付流程,實現配置變更審核與回滾。