【チュートリアル】ゼロから始める企業級高可用 PostgreSQL クラスタの構築

著者序
本文は 私のブログサイト から転載しました。原文アドレス:【チュートリアル】ゼロから始める企業級高可用 PostgreSQL クラスタの構築
すべてが始まる前に、以下の事項にご注意ください:
- 本文は、あなたが既に【チュートリアル】ゼロから始める最小高可用 k3s クラスタの構築を完了していることを前提としています
- 本文で使用する開発環境は
ArchLinux+Fish Shellです。システム間のコマンド構文の違いにより、実際の状況に応じてコマンド形式を調整してください。 - 本文で使用するオブジェクトストレージサービスは S3 プロトコルに対応したオブジェクトストレージです。実際の状況に応じて設定方法を調整してください。
- 本文のコマンドは各種 CLI ツール(本文中に記載されているか、前置チュートリアルで記載されています。Linux システムの一般的な CLI ツールは本文中に記載されていません)に依存しています。CLI ツールのインストールプロセスは複雑で、各プラットフォームのインストール手順は一貫していないため、ここでは詳しく説明しません。公式ドキュメントのインストールチュートリアルを参照してください。
序論
PostgreSQL は最も機能が豊富なオープンソースリレーショナルデータベースです(具体的な利点についてはネット上で何度も紹介されているため、ここでは詳しく説明しません)。これは著者が最も使用しているリレーショナルデータベースでもあります(他にはありません)。したがって、本人のチュートリアルで使用するリレーショナルデータベースは一般的に PostgreSQL を中心としているため、このチュートリアルを Kubernetes 関連チュートリアルの非常に基本的な前置チュートリアルと見なすことができます。
次に、この CloudNativePG(CNPG)について説明します。それは何ですか?簡単に言えば、Kubernetes 上の PostgreSQL の特化版と見なすことができます。PostgreSQL のデプロイと管理プロセスを大幅に簡素化し、同時に企業級の要件を満たすために、高可用性(HA)、自動バックアップ、障害演習、自動スケーリングなど、多くの高度な機能を提供しています。
本チュートリアルは k3s + Longhorn に基づき、CloudNativePG と汎用の S3 互換オブジェクトストレージを使用して、ゼロから高可用 PostgreSQL クラスタを構築し、基本的なバックアップと運用操作を実演します。最後に、手動で障害を作成し、データベースの自動復旧能力をテストします。
前提条件
デプロイを開始する前に、以下の前提条件が満たされていることを確認してください:
基盤インフラストラクチャ
まず、【チュートリアル】ゼロから始める最小高可用 k3s クラスタの構築 のような最小高可用 k3s クラスタを準備する必要があります。
CLI ツール
チュートリアルを開始する前に、以下の CLI ツールを準備する必要があります:
kubectl。クラスタの管理に使用されます。前のチュートリアルでは、既にkubectlをインストールし、リモートクラスタの管理権限(kubeconfig)を設定しました。- 検証コマンド:
kubectl version --short - 理想的な出力:
Client Version: <client_version>を表示します。正常に接続されている場合は、追加でServer Version: <server_version>が返されます。
- 検証コマンド:
helm。Operator のデプロイに使用されます。前のチュートリアルでは、既にhelmをインストールし、リモートクラスタの管理権限(kubeconfig)を設定しました。- 検証コマンド:
helm version - 理想的な出力:
version.BuildInfoフィールドにVersion: <helm_version>、GitCommit: <commit_hash>などの情報が含まれています。
- 検証コマンド:
kubeseal。Kubernetes Secret を暗号化するために使用されます。公式チュートリアルを参照して自分でインストールしてください。- 検証コマンド:
kubeseal --version - 理想的な出力:
kubeseal version: <kubeseal_version>を出力します。
- 検証コマンド:
openssl。ランダムパスワードを生成するために使用されます。これは通常、システムに付属しています。ない場合は、公式チュートリアルを参照して自分でインストールしてください。- 検証コマンド:
openssl version - 理想的な出力:OpenSSL バージョン情報を出力します(例:
OpenSSL <openssl_version> ...)
- 検証コマンド:
サードパーティ基盤インフラストラクチャ
S3 互換のオブジェクトストレージサービスアカウント(AWS S3、Wasabi、Backblaze B2、または自構築 MinIO など)を準備し、Bucket を作成してアクセスキーにアクセスできることを確認する必要があります。
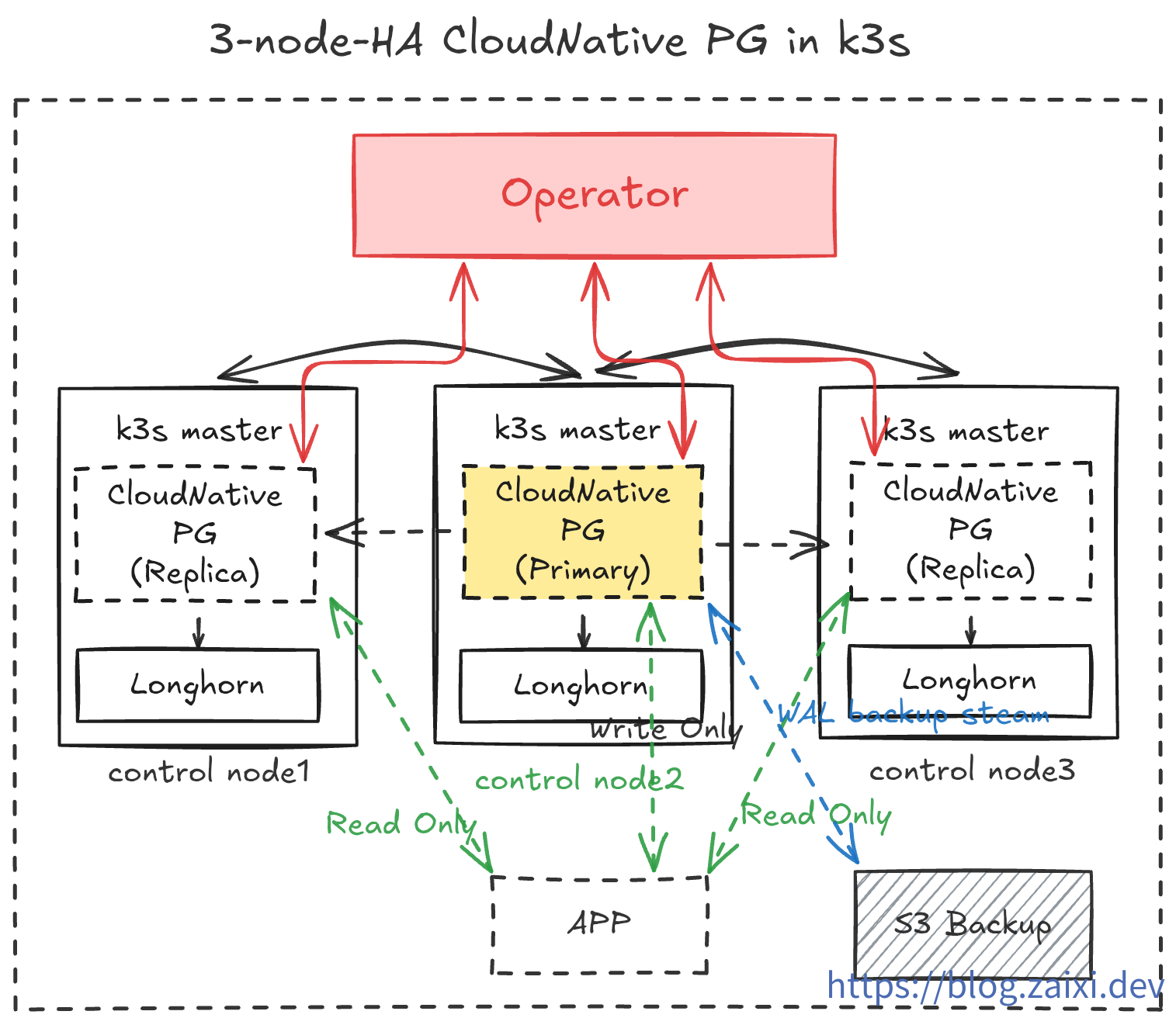
デプロイアーキテクチャ概要
本チュートリアルでは、以下の操作を実装します:
cnpg-system名前空間で CloudNativePG Operator を実行します。data-infra名前空間で 3 レプリカの PostgreSQL クラスタ(1 Primary + 2 Replica)を作成します。barman持続バックアップをオブジェクトストレージに有効にし、アプリケーション用に ReadWrite Service を公開します。cloudflaredサイドカーコンテナを使用して、データベースを安全に公開ネットワークに公開し、開発テストに使用します。- 運用演習。データベースのローリング更新とプラグインのインストールをテストします。
- 災害演習。ランダムにノードを爆発させ、自動復旧能力を観察します。極端な環境でオブジェクトストレージ内のバックアップデータを使用してデータベースを再構築するテストを実施します。
- 可観測性を実装し、
PrometheusとGrafanaを通じてデータベースの状態を監視します。
ステップ 1:CloudNativePG Operator のインストール
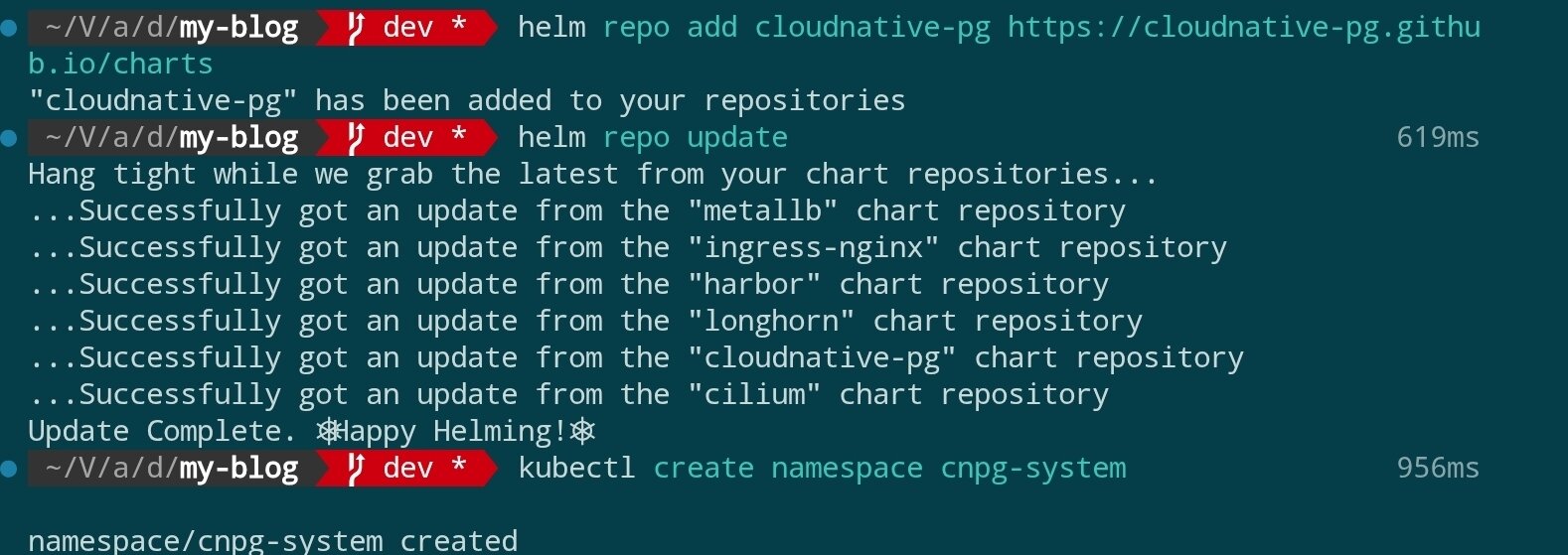
公式では Helm を使用した Operator のデプロイを推奨しています。まず Helm リポジトリを追加してインストールを完了します:
helm repo add cloudnative-pg https://cloudnative-pg.github.io/charts
helm repo update
kubectl create namespace cnpg-system
helm upgrade --install cloudnative-pg cloudnative-pg/cloudnative-pg \
--namespace cnpg-system \
--set controllerManager.resources.requests.cpu=200m \
--set controllerManager.resources.requests.memory=256Mi \
--set controllerManager.resources.limits.cpu=500m \
--set controllerManager.resources.limits.memory=512Mi
結果は以下の図のとおりです:

インストールコマンドパラメータの説明:
| パラメータ/フラグメント | 機能 | 備考 |
|---|---|---|
helm upgrade --install | Release が既に存在する場合はアップグレード、そうでない場合は初回インストール | デプロイコマンドをべき等に保つ |
cloudnative-pg | Helm Release の名前 | Helm がこのデプロイを追跡するために使用 |
cloudnative-pg/cloudnative-pg | Chart のリポジトリと名前 | 事前に helm repo add cloudnative-pg … が必要 |
--namespace cnpg-system | 使用する Kubernetes 名前空間 | Operator はこの名前空間で実行されます |
--set controllerManager.resources.requests.cpu=200m | Controller Manager がリクエストする最小 CPU | 最低 0.2 コアのスケジューリングを保証 |
--set controllerManager.resources.requests.memory=256Mi | Controller Manager がリクエストする最小メモリ | 最低 256Mi のスケジューリングを保証 |
--set controllerManager.resources.limits.cpu=500m | Controller Manager の CPU 上限 | 0.5 コアを超えると制限されます |
--set controllerManager.resources.limits.memory=512Mi | Controller Manager のメモリ上限 | 512Mi を超えると OOM がトリガーされる可能性があります |
Chart またはイメージバージョンを固定したい場合は、明示的に
--version <chartVersion>と--set image.tag=<controllerTag>を追加できます。これらのパラメータを省略すると、Helm はリポジトリの現在の最新安定版と Chart のデフォルトイメージを使用します。
スケジューリングメカニズムの補足:
controllerManagerPod は Kubernetes Scheduler によってスケジュールされます。まずリソースリクエスト(最低 200m CPU と 256Mi メモリ)を満たさないノードをフィルタリングし、次にクラスタの現在の負荷に基づいてスコアリングし、最終的に最適なノードを選択します。追加のnodeSelector、汚染容認、またはアフィニティ設定がない場合、任意の条件を満たすノードに落ちる可能性がありますが、結果はアルゴリズムとノードの状態に基づいて計算され、完全にランダムではありません。
クラスタが
kube-router、Ciliumなどのネットワークポリシーを有効にしている場合は、cnpg-system名前空間内のコントローラが Kubernetes API とターゲット名前空間にアクセスできることを確認してください。
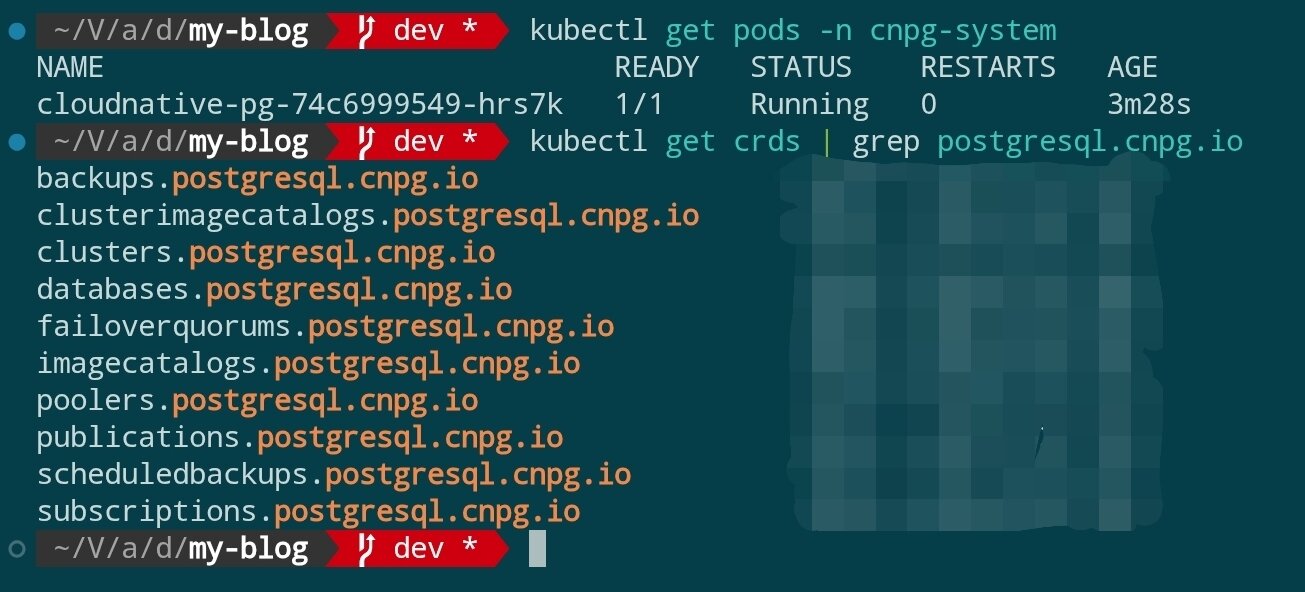
インストール完了後、Operator が準備完了しているかを確認します:
kubectl get pods -n cnpg-system
kubectl get crds | grep postgresql.cnpg.io
cluster.postgresql.cnpg.io などの CRD が登録され、Operator Pod が Running 状態にあることが確認できるはずです。
ステップ 2:名前空間とアクセス認証情報の準備
Sealed Secrets のインストール
本チュートリアルでは、Sealed Secrets を使用して機密情報を管理する必要があります。Sealed Secrets を使用する前に、クラスタにコントローラをデプロイし、ローカルに kubeseal CLI をインストールする必要があります:
よくある質問
- Q:なぜ Sealed Secrets を導入する必要があるのですか?
A:Sealed Secrets は Kubernetes Secret を Git に安全に保存できるマニフェストに暗号化できます。バージョンリポジトリに保存されても平文は漏洩しません。クラスタ側のコントローラは権限に応じて解封して実際の Secret を生成し、機密設定を標準 GitOps フローで同期できるようにします。
helm repo add sealed-secrets https://bitnami-labs.github.io/sealed-secrets
helm repo update
kubectl create namespace sealed-secrets
helm upgrade --install sealed-secrets sealed-secrets/sealed-secrets \
--namespace sealed-secrets \
--set fullnameOverride=sealed-secrets-controller
上記のコマンドは
sealed-secrets名前空間でコントローラを実行し、名前をsealed-secrets-controllerに固定します。これは後続の例で参照しやすくするためです。クラスタに既存のデプロイがある場合は、このステップをスキップできます。
次に、ローカルに kubeseal をインストールし、kubeseal --version を実行してバージョンを確認します。公式インストールチュートリアルを参照してください。

注意:
kubesealはデフォルトでkube-system名前空間でsealed-secrets-controllerという名前のサービスを探します。例のようにsealed-secrets名前空間に配置され、パラメータが指定されていない場合、error: cannot get sealed secret service: services "sealed-secrets-controller" not foundが表示されます。したがって、後続のコマンドは必ず--controller-namespace sealed-secrets --controller-name sealed-secrets-controllerを明示的に渡すか、実際のインストール場所に応じて調整してください。
よくある質問
- Q:
kubesealを実行するとerror: cannot get sealed secret service: services "sealed-secrets-controller" not foundというエラーが表示されるのはなぜですか?
A:kubesealはデフォルトでkube-system名前空間で同名のサービスを探します。例ではコントローラをsealed-secrets名前空間にデプロイしているため、--controller-namespace sealed-secrets --controller-name sealed-secrets-controllerを追加する必要があります。そうしないと見つかりません。 - Q:それなら、
kubesealがデフォルトで見つけられるkube-system名前空間にサービスを直接デプロイしないのはなぜですか?
A:主に分離と保守性のためです。kube-systemは通常、クラスタの下位レイヤーコンポーネントによって占有されており、その名前空間をきれいに保つことで問題の診断が容易になります。同時に、独立したsealed-secrets名前空間は関連リソースを集中管理でき、マルチ環境またはマルチテナント時にも権限制御が容易です。ツールがデフォルトでkube-systemを指すのは、一般的なインストール方法との互換性のためです。実際のデプロイに応じてパラメータを渡すだけで十分です。
ビジネス Secret の生成
データベースレイヤー用に独立した名前空間を準備し、Sealed Secrets を使用して機密情報を管理し、雑多なリソースが同じスペースに混在するのを避けます:
kubectl create namespace data-infra
データベースアプリケーションアカウントの暗号化 Secret を生成します:
ステップ 1:元の Secret マニフェストを生成します(クラスタに書き込まれません)
kubectl create secret generic cnpg-app-user \
--namespace data-infra \
--from-literal=username=app_user \
--from-literal=password="$(openssl rand -base64 20)" \
--dry-run=client -o json > cnpg-app-user.secret.json
このコマンドは、ユーザー名とランダムパスワードを Kubernetes Secret の JSON マニフェストにカプセル化し、cnpg-app-user.secret.json に書き込みます。同時にクラスタへの副作用を保ちます。生成されたファイルの内容は以下のようなものです:
{
"kind": "Secret",
"apiVersion": "v1",
"metadata": {
"name": "cnpg-app-user",
"namespace": "data-infra"
},
"data": {
"password": "random-password",
"username": "random-username"
}
}
ステップ 2:kubeseal を使用して SealedSecret に暗号化します
kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml < cnpg-app-user.secret.json > cnpg-app-user.sealed-secret.yaml
ここで前のステップの JSON を手動で読み込み、kubeseal に渡します。名前空間とコントローラパラメータにより、CLI がデプロイした Sealed Secrets コントローラに接続できることを確認します。--format yaml は Git にコミットできる SealedSecret ファイルを出力します。ここで生成されたファイルの内容は以下のようなものです:
---
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: cnpg-app-user
namespace: data-infra
spec:
encryptedData:
password: random-password(locked)
username: random-username(locked)
template:
metadata:
name: cnpg-app-user
namespace: data-infra
ステップ 3:SealedSecret をクラスタに適用し、元の Secret を削除します
kubectl apply -f cnpg-app-user.sealed-secret.yaml
rm cnpg-app-user.secret.json
コントローラが受け取った後、自動的に解封して同名の通常 Secret(cnpg-app-user)を生成します。これは後続のデータベースリソースで参照されます。cnpg-app-user.sealed-secret.yaml を適切に保管し、後続の CI/CD フローで使用できるようにしてください。
S3 互換オブジェクトストレージ認証情報の準備
- オブジェクトストレージサービスコンソール(AWS S3、Wasabi、Backblaze B2、または自構築 MinIO クラスタなど)にログインし、本チュートリアル用の専用 Bucket を新規作成します。例として
cnpg-backupという名前を付け、Region は Kubernetes クラスタに最も近い地域を選択します。 - Bucket のアクセスポリシーで公開読み取り/書き込みを無効にし、認証情報アクセスのみを許可します。供給業者がライフサイクルまたはバージョン管理をサポートしている場合は、コンプライアンス要件に応じて事前に設定できます。
- 認証情報またはキー管理ページに移動し、本チュートリアル用のアクセスキーペアを作成します。最低限、ターゲット Bucket の
Object ReadとObject Write権限を付与し、必要に応じて特定のプレフィックス範囲に制限できます。 - コンソールが返す
Access Key ID、Secret Access Key、Region(該当する場合)、および S3 Endpoint(例:https://s3.ap-northeast-1.amazonaws.comまたは供給業者が提供するカスタムドメイン)を記録します。一部の供給業者は Path Style アクセスが必要かどうかを注記します。同時に記録してください。 - この情報をパスワードマネージャーに保存し、後続で Kubernetes Secret に書き込む平文値を準備します:
aws_access_key_id、aws_secret_access_key、region(Region が固定されていない場合は供給業者の推奨値を入力)。同時に、CNPG で使用されるdestinationPath(例:s3://my-cnpg-backups/production)を確認します。
コンソール設定を完了した後、Sealed Secrets を使用してこのグループの認証情報を管理できます。
SealedSecret を使用したオブジェクトストレージ認証情報の設定
オブジェクトストレージバックアップを有効にする場合、同様に Sealed Secrets を使用してアクセス認証情報を生成します(S3 互換サービスの例):
kubectl create secret generic cnpg-backup-s3 \
--namespace data-infra \
--from-literal=aws_access_key_id=AKIA... \
--from-literal=aws_secret_access_key=xxxxxxxxxxxx \
--from-literal=region=ap-northeast-1 \
--dry-run=client -o json \
| kubeseal \
--controller-namespace sealed-secrets \
--controller-name sealed-secrets-controller \
--format yaml > cnpg-backup-s3.sealed-secret.yaml
kubectl apply -f cnpg-backup-s3.sealed-secret.yaml
ステップ 3:PostgreSQL クラスタの宣言
CloudNativePG は Cluster カスタムリソースを使用してデータベーススタックを定義します。以下は本番環境に適したサンプルです(ストレージクラスは前のチュートリアルでデプロイした Longhorn を使用):
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cnpg-ha
namespace: data-infra
spec:
instances: 3
imageName: ghcr.io/cloudnative-pg/postgresql:16.4
primaryUpdateStrategy: unsupervised
storage:
size: 40Gi
storageClass: longhorn
postgresql:
parameters:
max_connections: "200"
shared_buffers: "512MB"
wal_level: logical
pg_hba:
- hostssl all all 0.0.0.0/0 md5
authentication:
superuser:
secret:
name: cnpg-app-user
replication:
secret:
name: cnpg-app-user
bootstrap:
initdb:
database: appdb
owner: app_user
secret:
name: cnpg-app-user
backup:
barmanObjectStore:
destinationPath: s3://my-cnpg-backups/production
endpointURL: https://s3.ap-northeast-1.amazonaws.com
s3Credentials:
accessKeyId:
name: cnpg-backup-s3
key: aws_access_key_id
secretAccessKey:
name: cnpg-backup-s3
key: aws_secret_access_key
region:
name: cnpg-backup-s3
key: region
retentionPolicy: "14d"
monitoring:
enablePodMonitor: true
cnpg-ha.yaml として保存して適用します:
kubectl apply -f cnpg-ha.yaml
CNPG は自動的に StatefulSet、PVC、サービスなどのリソースを作成します。Pod の起動完了を待ちます:
kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha -w
Primary と Replica の両方が Running 状態になると、データベースクラスタのデプロイが完了します。
ステップ 4:高可用性とサービス公開の検証
サービスと接続情報の確認
kubectl get svc -n data-infra -l cnpg.io/cluster=cnpg-ha
kubectl port-forward svc/cnpg-ha-rw 6432:5432 -n data-infra
psql "postgresql://app_user:$(kubectl get secret cnpg-app-user -n data-infra -o jsonpath='{.data.password}' | base64 -d)@127.0.0.1:6432/appdb"
CNPG はデフォルトで -rw(読み取り/書き込み)と -ro(読み取り専用)Service を作成し、アプリケーションがそれぞれプライマリデータベースとレプリカデータベースに接続しやすくします。
障害フェイルオーバーのシミュレーション
Primary Pod を強制的に削除して自動復旧能力を検証します:
kubectl delete pod -n data-infra \
$(kubectl get pods -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary -o jsonpath='{.items[0].metadata.name}')
数秒以内に、CNPG は自動的に Replica の 1 つを Primary に昇格させます。以下のコマンドでロール変更を確認します:
kubectl get pods -n data-infra -L role
kubectl logs -n data-infra -l cnpg.io/cluster=cnpg-ha,role=primary --tail=20
ステップ 5:バックアップと災害復旧戦略
- 持続バックアップ(PITR):
barmanObjectStore設定は WAL を継続的にオブジェクトストレージに書き込み、kubectl cnpg backupコマンドで全量バックアップをトリガーできます。 - 定期的な復旧演習:一時的な名前空間で
Backup+ClusterCR を作成し、オブジェクトストレージから指定時点への復旧を検証します。 - 監視とアラート:
monitoring.enablePodMonitorを有効にした後、Prometheus でcnpg_pg_replication_lag、cnpg_pg_is_in_recoveryなどの重要指標を取得できます。 - リソースクォータ:
data-infra名前空間にLimitRangeとResourceQuotaを設定し、データベースインスタンスがノードリソースを圧迫するのを防ぎます。
一般的な運用操作
- オンライン拡張:
spec.instancesの数を調整するだけで、CNPG は自動的に新しい Replica を作成してデータを同期します。 - パラメータ調整:
spec.postgresql.parametersを更新すると、Operator はローリング再起動をトリガーして設定を下発します。 - バージョンアップグレード:
spec.imageNameを変更して新しいバージョンのイメージを指定すると、CNPG は最初に新しい Replica を作成し、switchoverを実行した後に古い Primary を回収します。 - 論理レプリケーション:
pg_hbaとwal_level設定を通じて、特定のデータベース/テーブルを外部データウェアハウスに同期できます。
まとめと次のステップ
これで、高可用 k3s クラスタに自動フェイルオーバー、持続バックアップ、宣言型管理機能を備えた PostgreSQL クラスタをデプロイしました。次のステップは以下を検討できます:
- Grafana Loki または ELK を導入してデータベースログを収集し、可観測性を改善します。
- CloudNativePG Pooler または PgBouncer を使用して接続プール管理を最適化します。
- Argo CD/Fleet などの GitOps ツールと組み合わせて、データベース CR を継続的デリバリーフローに組み込み、設定変更の審査とロールバックを実現します。